How to Model Data by Refactoring SQL - Level 2
In a previous article we talked about how to refactor SQL code to improve readability and maintainability. That example applied to a single query. Now we're ready to take it to the next step and go across queries.
In this example we're going to be looking at production-level dbt code and see how we can improve it. In the process, we'll see how to use refactoring to model data.
Without further ado let's get into it.
Let's take a look at this dbt model in the mattermost repo.
I'm not going to reproduce the entire code here since it's too long, but you should pull it up alongside this post for reference, or just read the code snippets I'll provide screenshots for.
By the way, I don't have access to the database so I'm not going to actually rewrite this code. That would require actual testing to make sure the output is the same, and that's incredibly time consuming.
This code is a dbt model that builds a funnel table which I'm guessing is used to evaluate sales performance.
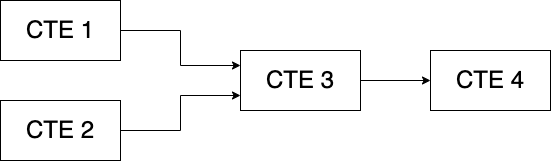
The first thing I notice is that the code is using CTEs to break up the various sales stages, exactly as I suggested in the level 1 refactoring article referenced above.
Let's skip over the months and key_assumptions CTEs since they're not that interesting and look at the web_traffic CTE.
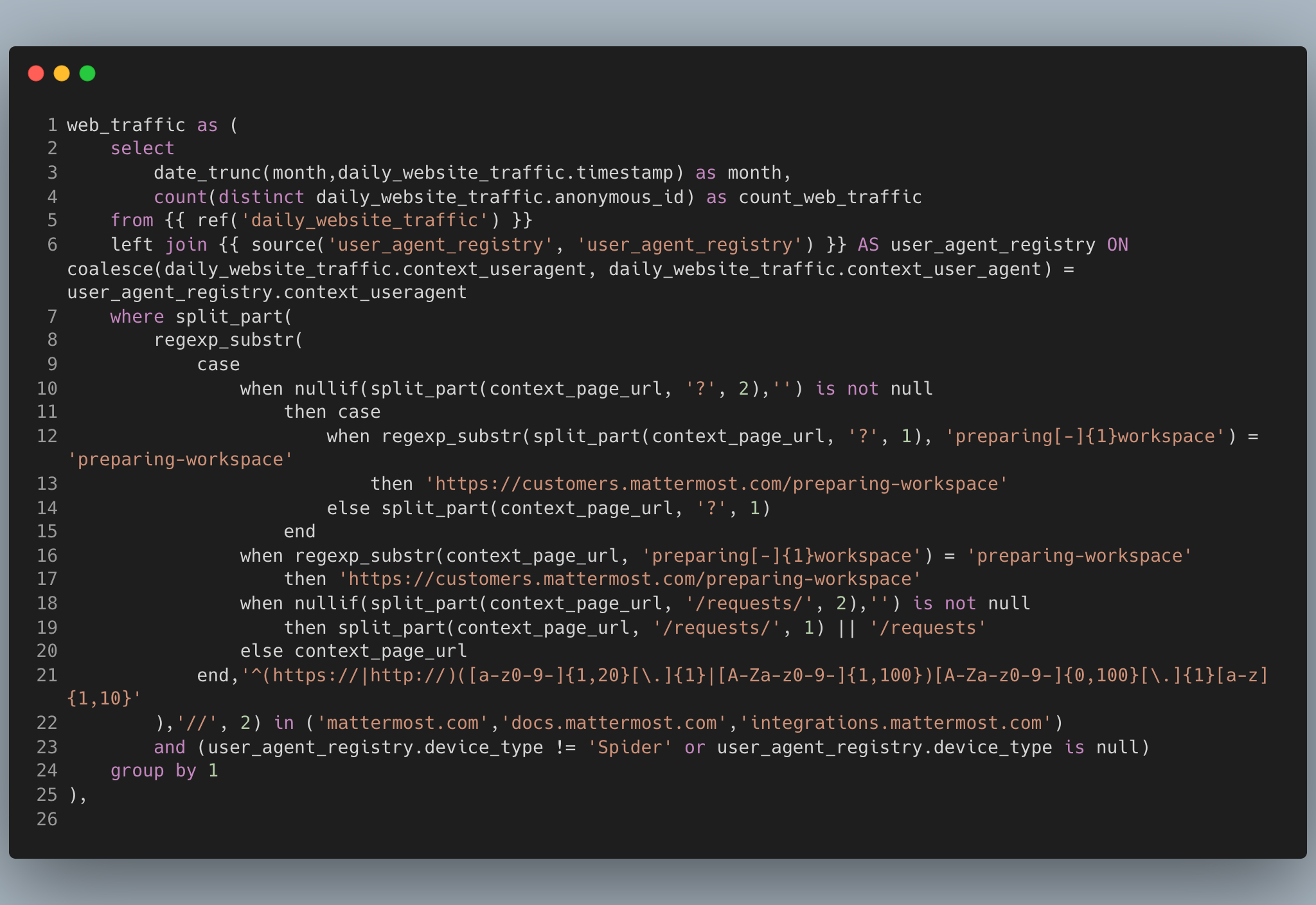
It seems that this query is pulling traffic data from the raw table daily_website_traffic and through regular expressions, I think it's trying to limit the traffic to certain domains.
I can't be sure that I'm right, but that's not the point here. I would highly recommend this code be moved upstream to adaily_website_traffic model and either you filter it there, or you create attributes that define "mattermost traffic."
Remember our 3rd principle "Move Logic Upstream" from the modularity article? By moving the logic upstream, you unlock downstream use cases for this model. If adaily_website_traffic is ever needed again, you don't have to copy/paste this code. And if you need to change the logic in any way, you make the changes in one place.
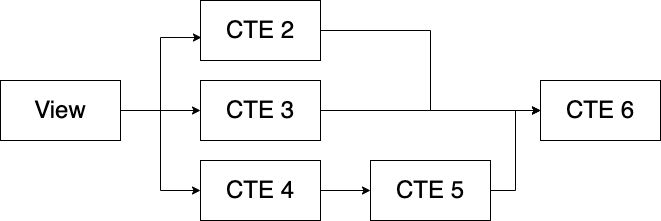
Let's look at another example in the same file.
The next 4 CTEs (lead_creation, mql reengaged_mql and sal) all reference the raw leads table as it's pulled from source (Salesforce or another CRM)
Notice how the condition in the where clause is repeated every time. Remember our DRY principle from the modularity article?
This repetition is wasteful and really hard to maintain. Make one mistake in pasting and you'll be spending the next several hours debugging data issues.
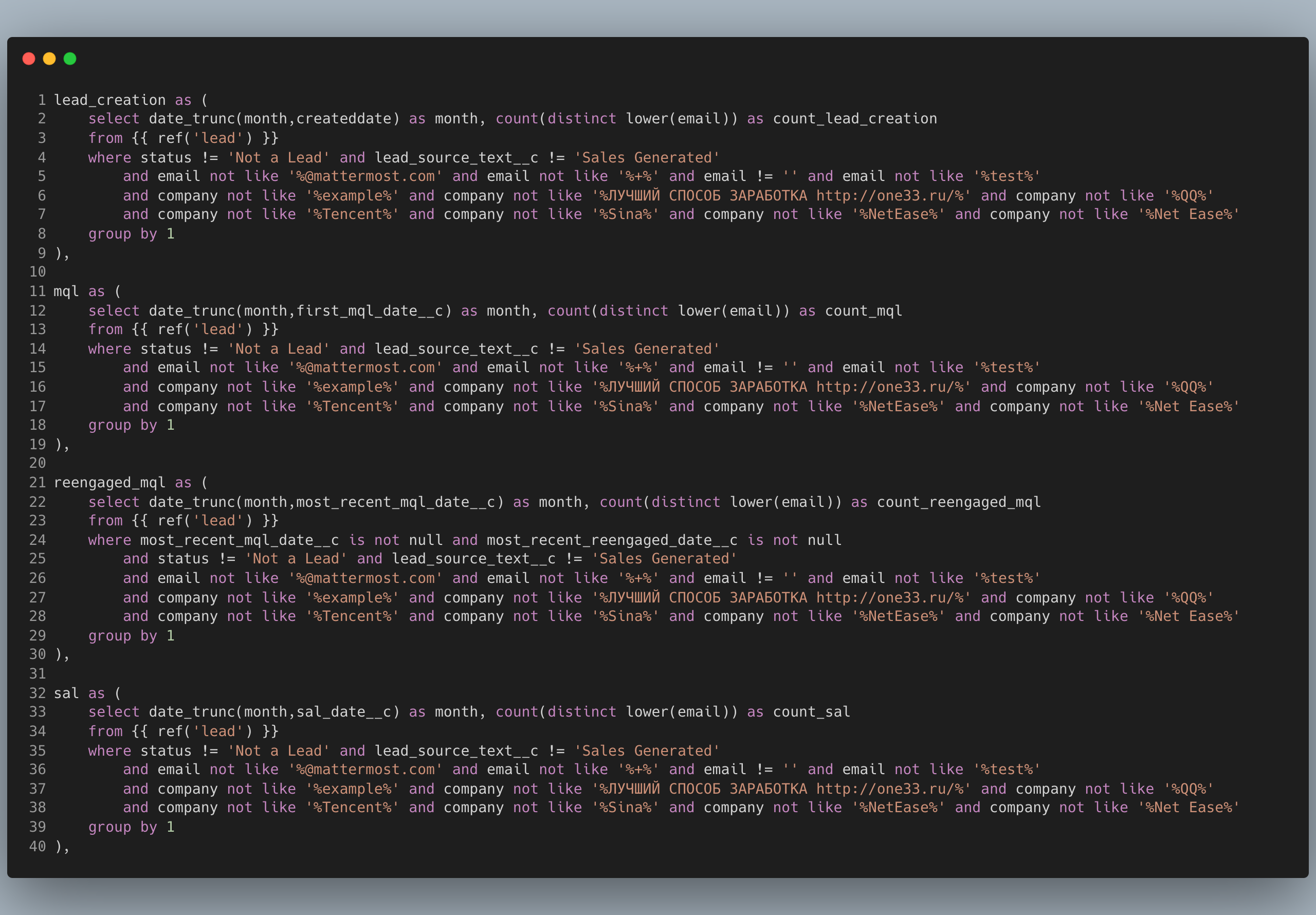
Again we can apply both the DRY principle and move logic upstream by creating a leads model that handles the filtering and has all the necessary attributes such as createddate, first_mql_date, most_recent_mql_date and so on. All you'd have to do is reference the model and not worry about the details.
Here's an example of what that might look like. I don't recommend this by the way, I think the code in all_leads belongs in the leads model but to illustrate the pattern, I'll do a quick refactor.
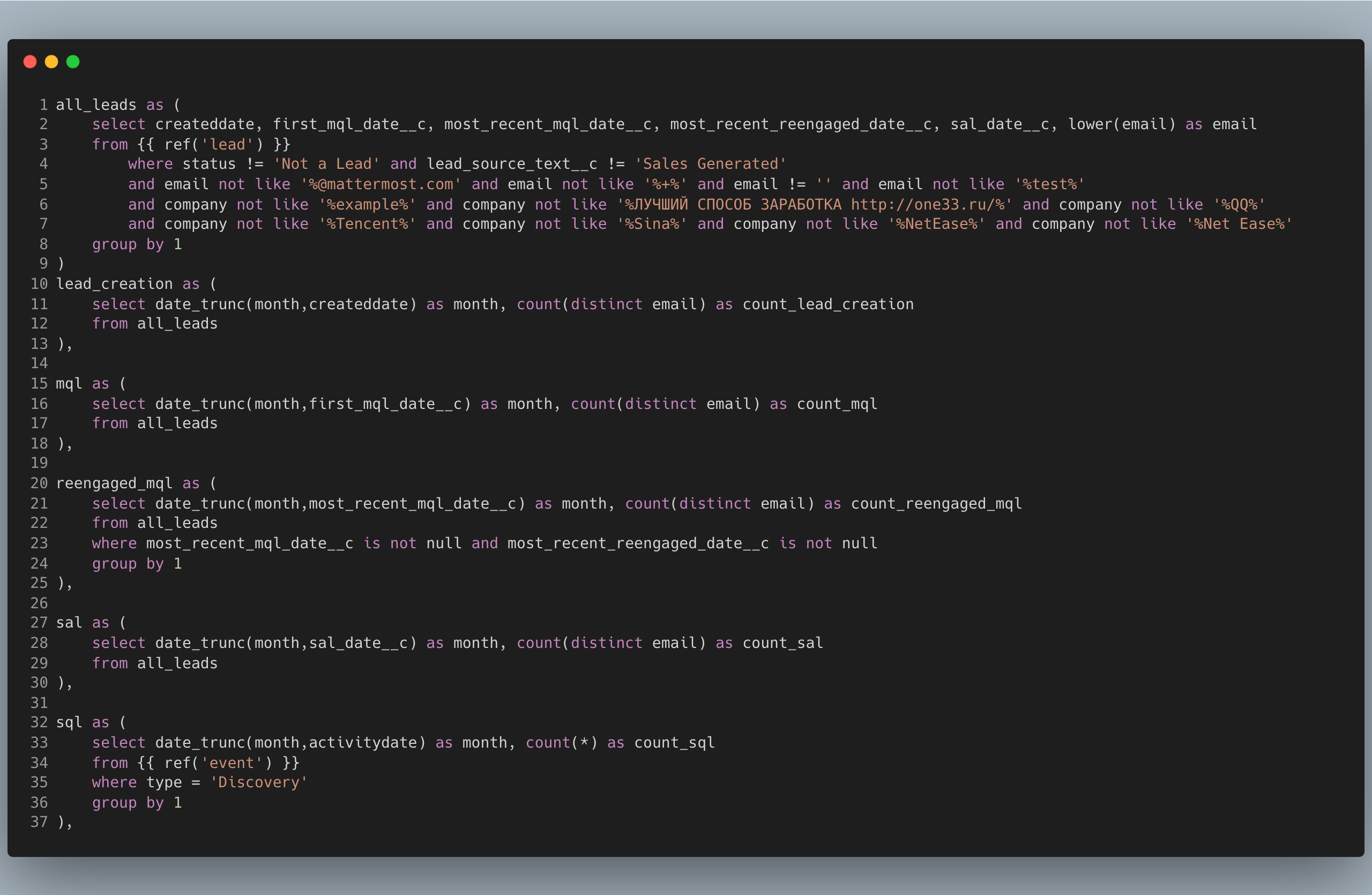
The traditional modeling approach is to define everything you need upfront. So a data engineer or architect would get together with the business owners and ask them about all the concepts they care about in the business.
Leads is a very important concept in many business models, especially if you're paying to acquire them. The Leads concept might have attributes such as email, creation_date, source, etc.
By creating this abstract concept in your data warehouse with all the attributes you want to track, you've created a type of data "contract" which basically says regardless of how leads are implemented in the operational systems, I want these attributes mapped.
But this is just one way to do modeling. It suffers from what's called a BDUF (big design upfront) and it's not agile. Most programming these days is done in rapid iteration (known as sprints) where you deliver working code at each step.
Can we do the same for data?
I think we can, but we need brave analytics / data engineers who are not scared of mucking about in the guts of a dbt repository. The moment you see WET code (Write Everything Twice) or logic that can be moved upstream, you do it.
One of the core benefits of modeling this way, outside of making code more readable, easier to maintain and debug, is that it creates durable concepts. With a Leads object in place, we can worry less about the actual implementation.
If tomorrow the CTO decides to swap out the CRM for a new system, you only need to change one model to map the new fields and your warehouse keeps working.