Exploring the ActivitySchema
Introduction
Ever since I read about the ActivitySchema I've been fascinated with it and have wanted to try it out. The only problem is that the only tool that implements it is Narrator and there aren't a lot of companies using it yet. I also didn't have a good enough dataset to try it on.
Then a friend asked me to help him do some analytics for his Shopify store. I got some of the data stored in BigQuery and Narrator has ready-made activities for it, I decided to give it a try. Unfortunately his Facebook campaigns weren't tagged properly and he only used the free Google Analytics setup on his site so I couldn't do deeper analysis.
In this series of posts, I'll explore what I've learned about the Activity schema and hopefully provide some insight into this new modeling technique. In the first post we'll explore the table and how to set that up. In the upcoming posts we'll cover the various SQL queries that let you explore this table.
One table to rule them all
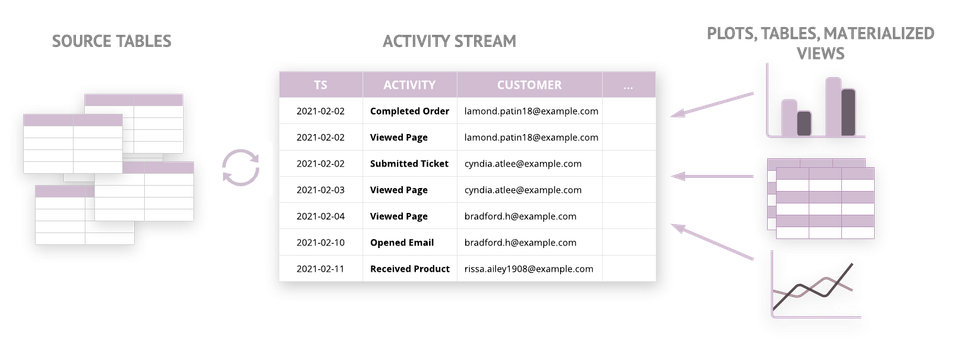
Activity schema is based on the idea of a single time-series table that conforms all customer activities to a fixed 11 column schema. You only need 11 columns to express your entire customer journey and to build all the analyses around it.
I will not go into a lot of details about the table and the schema since you can read all about it in the github repo.
Having done my fair share of modeling in the past I immediately recognized the benefits of the activity schema:
- Each activity is an isolated event that never changes. This makes each activity immutable (unchanging) and the activity stream table append-only. What that means is that when something changes in the future, I don't have to modify past records to update them like you have to do with dimensional modeling or ER diagrams. You just add more activities.
- You don't have to worry about slowly changing dimensions or late arriving facts, you just append them all in the table, again using activities. We'll cover this later.
- Because the schema is standardized regardless of the activities, querying the model becomes very predictable once you figure out the basics. You're basically joining activities for the same customer in time through the help of temporal relationships.
- There are only 11 temporal relationships which means that almost every question you can think of can be reduced to one or many of these 11 temporal relationships. We'll explore them one by one later as well.
Constructing the table
Without further ado, let's get into how to build the table. Like I said earlier, I used Shopify data from a friend's store, so unfortunately I cannot show the results of the queries, but the patterns should be pretty clear. I'm using BigQuery for my experiments.
Creating the table is pretty straightforward:
create or replace table my_data.customer_stream (
activity_id string,
ts timestamp,
activity string,
customer string,
anonymous_customer_id string,
feature_1 string,
feature_2 string,
feature_3 string,
revenue_impact float64,
link string,
activity_occurrence int64,
activity_repeated_at timestamp
);
While that's pretty simple, there are a few things I discovered as I was building the table:
- Each
activity - timestamp - customerrow MUST be unique. If there are duplicates aggregate queries will be wrong activity_ocurrenceandacitivty_repeated_atmust be updated AFTER the table has been populated. My query updates the entire table, but you can limit the updates by filtering on the activity you're inserting so you can keep costs low.
Here's the script for updating those columns:
update my_data.customer_stream a
set activity_occurrence = dt.activity_occurrence,
activity_repeated_at = dt.activity_repeated_at
from (
select
activity_id,
customer,
activity,
ts,
row_number() over each_activity as activity_occurrence,
lead(ts,1) over each_activity as activity_repeated_at
from
my_data.customer_stream
window
each_activity as (partition by customer, activity order by ts asc)
)dt
where
dt.activity_id = a.activity_id
and dt.customer = a.customer
and dt.activity = a.activity
and a.ts = dt.ts;
Loading Shopify data
Narrator lists all the the queries for Shopify here I didn't use all the activities so I'll just mention the ones I used.
Started Checkout
Customer started a checkout session
insert into my_data.customer_stream
(
activity_id,
ts,
activity,
customer,
anonymous_customer_id,
feature_1,
feature_2,
feature_3,
revenue_impact
)
select
cast(c.id as string) as activity_id,
c.created_at as ts,
'started_checkout' as activity,
coalesce(lower(c.email), lower(o.email)) as customer,
c.token as anonymous_customer_id,
cast(o.total_line_items_price as string) as feature_1,
c.shipping_address_country_code as feature_2,
cast(c.total_tax as string) as feature_3,
c.total_price - c.total_discounts as revenue_impact
from
shopify.abandoned_checkout as c
left join shopify.order as o
on c.token = o.checkout_token
where
c.created_at is not null
/* ensure customer + activity + ts is unique in the whole table */
and not exists (select *
from my_data.customer_stream
where customer = coalesce(lower(c.email), lower(o.email), '')
and activity = 'started_checkout'
and ts = c.created_at
);
A couple of things to notice:
- We omit some of the the columns here because we don't have values for them. This is ok since you won't always have values for them.
- The
WHEREclause is checking for duplicates at the customer, activity, timestamp level like we said above. This is crucial.
Completed order
Customer completed the checkout process
insert into my_data.customer_stream
(
activity_id,
ts,
activity,
customer,
anonymous_customer_id,
feature_1,
feature_2,
feature_3,
revenue_impact
)
select
cast(o.id as string) as activity_id,
o.processed_at as ts,
'completed_order' as activity,
lower(o.email) as customer,
null as anonymous_customer_id,
d.code as feature_1, -- discount code
o.name as feature_2, -- order name
o.processing_method as feature_3,
-- this is the merchandize_price with discounts applied
o.subtotal_price as revenue_impact
from
shopify.order as o
left join shopify.order_discount_code d
on d.order_id = o.id
where
o.cancelled_at is null
and o.email is not null
and o.email <> ''
/* ensure customer + activity + ts is unique in the whole table */
and not exists (select *
from my_data.customer_stream
where customer = lower(o.email)
and activity = 'completed_order'
and ts = o.processed_at
);
Shipped order
The order has now been shipped
insert into my_data.customer_stream
(
activity_id,
ts,
activity,
customer,
anonymous_customer_id,
feature_1,
feature_2,
feature_3,
link
)
select
cast(f.id as string) as activity_id,
f.created_at as ts,
'shipped_order' as activity,
lower(o.email) as customer,
null as anonymous_customer_id,
o.name as feature_1,
f.tracking_company as feature_2,
l.name as feature_3,
null as revenue_impact,
case f.tracking_company
when 'FedEx' then 'https://www.fedex.com/apps/fedextrack/?tracknumbers=' || f.tracking_number
when 'Canada Post' then 'https://www.canadapost.ca/trackweb/en#/search?searchFor=' || f.tracking_number
when 'USPS' then 'https://tools.usps.com/go/TrackConfirmAction?qtc_tLabels1=' || f.tracking_number
when 'Stamps.com' then 'https://tools.usps.com/go/TrackConfirmAction?qtc_tLabels1=' || f.tracking_number
when 'DHL eCommerce' then 'https://www.dhl.com/en/express/tracking.html?brand=DHL&AWB=' || f.tracking_number
end as link,
null as activity_occurrence,
null as activity_repeated_at
from
shopify.fulfillment f
left outer join shopify.location l
on f.location_id = l.id
join shopify.order as o
on f.order_id = o.id
where
o.cancelled_at is null
/* ensure customer + activity + ts is unique in the whole table */
and not exists (select *
from my_data.customer_stream
where customer = lower(o.email)
and activity = 'shipped_order'
and ts = f.created_at
);
Order enrichment table
On the rare occasion that you need more dimensions beyond the 3 features, you can create an optional enrichment table. Ideally this table is also immutable so you don't have to worry about maintaining history.
create or replace table my_data.order_enrichment
as
select
cast(o.id as string) as enriched_activity_id,
o.created_at as enriched_ts,
o.subtotal_price as subtotal_price,
o.total_price as total_price,
o.total_tax as tax,
s.price as shipping_price,
s.title as shipping_kind,
o.total_discounts,
o.total_weight
from
shopify.order as o
left join shopify.order_shipping_line s
on o.id = s.order_id
This table can easily be joined to the activity stream via the enriched_activity_id which is just the order_id and enriched_ts
You can add more activities to the table but we'll stop here for the time being. In Part 2 we'll get into exploring the 11 activities.
Additional considerations
There are a few things that came up during this exercise that I don't see explained.
The table can easily be created manually, but keeping it updated needs to be automated. Narrator does this natively but if you don't have that tool, you need a way to run the insert scripts. A tool like Airflow could be used for this purpose but I haven't tried to do it myself.
Maintaining the mapping between each activity and its features is another thing Narrator handles natively. This is much harder to do manually. You can create a mapping table like the one below, but that doesn't solve the problem of naming columns at query time. That solution would require dynamic SQL.You'd need to know what each feature of each activity means.
create or replace table reports.features
(
activity string,
feature1 string,
feature2 string,
feature3 string
)
as
select
'completed_order' as activity,
'discount_code' as feature1,
'order_name' as feature2,
'processing_method' as feature3
Querying the Table
Querying such a table is very different than the traditional way of using keys. Since activities for the customer are strung together in time, the relations amongst them are temporal in nature. When you join one or many activities, you're essentially figuring out how to link them with each other by using the customer id and the timestamp.
Let's take a look at an example.
ts |activity |customer|activity_repeated_at|
-------------------+-----------------+--------+--------------------+
2020-10-21 20:27:08|started_session |12345 |2020-11-16 14:41:27 |
2020-10-25 16:39:51|started_checkout |12345 |2020-11-17 17:50:13 |
2020-10-28 15:19:33|completed_order |12345 |2020-11-17 18:15:13 |
2020-10-28 15:36:05|shipped_order |12345 | |
2020-11-16 14:41:27|started_session |12345 | |
2020-11-17 17:50:13|started_checkout |12345 | |
2020-11-17 18:15:13|completed_order |12345 | |
As you can see this customer's journey begins by starting a web session (assuming of course we've identified them, more on that later) and then a few days later they start a checkout, complete the order and it gets shipped. Then they start another web session a few weeks later.
This is what an ActivitySchema is supposed to look like. We've stitched together activities from multiple tools (web logging and Shopify) into a singular customer view with a conformed schema. This allows us to answer almost any question about the customer as long as it can be phrased in a temporal relationship.
Temporal Relationships
In order to stitch activities together in time we have to join them through the customer, activity and timestamp fields and we can then pivot the features out into their own columns in order to enrich our data set. There are 11 such relationships and we'll cover each one separately.
- First ever
- Last ever
- First before
- Last before
- First after
- First in between
- Last in between
- Aggregate all ever
- Aggregate before
- Aggregate after
- Aggregate in between
The way you join activities together is by starting with a base activity (your initial cohort) and you append other activities to it based on whether those activities occurred before all the base activities, after all the base activities or in between them and whether we care about the first occurrence or the last occurrence.
First Ever
In this part we're going to cover the First Ever and Last Ever relationships. The First Ever relationship means that you attach the first occurrence of that activity to the cohort you start with regardless of when that base activity happened. The same happens with the Last Ever, you attach the last activity that happened regardless of when it happened.
These can be very useful when you want to do say first-touch or last-touch attribution for a customer. In this case your cohort is everyone who has a completed_order activity and you join or append to that the first occurrence of a stated_session activity.
You can see in results above that customer 12345 started a session on 2020-10-21 20:27:08 and then another one on 2020-11-16 14:41:27 They also completed two orders. So if I was doing a First Ever relationship, I would start with the completed_order activity as my cohort like this:
with cohort as (
select
activity_id,
datetime(ts, 'America/New_York') as activity_timestamp,
activity,
customer,
activity_occurrence,
feature_1,
feature_2,
feature_3,
ts as join_ts,
activity_id as join_cohort_id,
customer as join_customer,
activity_repeated_at as join_cohort_next_ts
from
my_data.customer_stream
where
activity = 'completed_order'
order by
ts desc
)
This would get me both order completed activities:
ts |activity |customer|
-------------------+-----------------+--------+
2020-10-28 15:19:33|completed_order |12345 |
2020-11-17 18:15:13|completed_order |12345 |
Then I would grab the first ever session_started like this:
first_ever_checkout_started as (
select
join_customer,
join_cohort_id,
min(cs.ts) as first_session_started_at
from
cohort c
inner join my_data.customer_stream cs
on c.join_customer = cs.customer
where
cs.activity = 'session_started'
group by
1,2
)
Then if I wanted to grab all the features of the session_started activity, all I'd need to do is join that activity on customer and timestamp like this:
first_ever_session_started_features as (
select
fe.join_customer,
fe.join_cohort_id,
fe.first_session_started_at,
s.activity,
s.feature_1,
s.feature_2,
s.feature_3,
s.link
from
my_data.customer_stream s
inner join first_ever_session_started fe
on s.customer = fe.join_customer
and s.ts = fe.first_session_started_at
where
s.activity = 'session_started'
)
Finally, I would join the two and pivot out the features that I wanted like this:
This final query would repeat the features of the first ever session_started activity for every order_completed activity which would allow us to perform the right attribution.
Here's the full query:
--first ever
with cohort as (
select
activity_id,
datetime(ts, 'America/New_York') as activity_timestamp,
activity,
customer,
activity_occurrence,
feature_1,
feature_2,
feature_3,
ts as join_ts,
activity_id as join_cohort_id,
customer as join_customer,
activity_repeated_at as join_cohort_next_ts
from
my_data.customer_stream
where
activity = 'completed_order'
order by
ts desc
),
first_ever_session_started as (
select
join_customer,
join_cohort_id,
min(cs.ts) as first_session_started_at
from
cohort c
inner join my_data.customer_stream cs
on c.join_customer = cs.customer
where
cs.activity = 'session_started'
group by
1,2
)
, first_ever_session_started_features as (
select
fe.join_customer,
fe.join_cohort_id,
fe.first_session_started_at,
s.activity,
s.feature_1,
s.feature_2,
s.feature_3,
s.link
from
my_data.customer_stream s
inner join first_ever_session_started fe
on s.customer = fe.join_customer
and s.ts = fe.first_session_started_at
where
s.activity = 'session_started'
)
select
c.activity_timestamp,
c.customer,
c.activity,
c.activity_occurrence,
c.feature_1,
c.feature_2,
c.feature_3,
datetime(fe.first_session_started_at, 'America/New_York') as first_session_started_at,
fe.activity,
fe.feature_1,
fe.feature_2,
fe.feature_3,
fe.link
from
cohort c
left outer join first_ever_session_started_features fe
on c.join_customer = fe.join_customer
and c.join_cohort_id = fe.join_cohort_id;
The same exact query (with a minor change) applies to Last Ever. All you have to do is change the min() function for the max() function in the second CTE. This is the key to the AcivitySchema. That's where all the magic of the temporal relationships happen.
Exploring the Other Relationships
Now that we saw how the basics work let's get a little more into it. Going forward I will not write the entire query since the only part that changes is the second CTE.
The First Before relationship looks at the first occurrence of the activity we want just before the cohort activity we're looking at. For example let's say we want the first session_started activity before checkout_started because we might want to measure how long it takes for a customer to start shopping once they come on the site.
Assuming our cohort is made up of session_started activities the query is quite simple
with cohort as (
select
activity_id,
....
ts as join_ts,
activity_id as join_cohort_id,
customer as join_customer,
activity_repeated_at as join_cohort_next_ts
from
my_data.customer_stream
where
activity = 'checkout_started'
order by
ts desc
),
append_first_before as (
select
join_customer,
join_cohort_id,
min(cs.ts) as first_before_ts
from
cohort c
inner join my_data.customer_stream cs
on c.join_customer = cs.customer
and cs.ts <= join_ts
where
cs.activity = 'session_started'
group by
1,2
)If you wanted the Last Before just flip the min() function to a max() and keep everything else the same. What about the First In Between? This is where the ingenious field activity_repeated_at comes into play. Without that field, you'd have to compute a window function on the fly and those can get pretty expensive.
The query is pretty much the same except the join condition changes. Again if you want to flip from first to last change the aggregate function from a min() to a max()
with cohort as (
select
activity_id,
....
ts as join_ts,
activity_id as join_cohort_id,
customer as join_customer,
activity_repeated_at as join_cohort_next_ts
from
my_data.customer_stream
where
activity = 'checkout_started'
order by
ts desc
),
append_first_before as (
select
join_customer,
join_cohort_id,
min(cs.ts) as first_before_ts
from
cohort c
inner join my_data.customer_stream cs
on c.join_customer = cs.customer
and cs.ts > join_ts
and cs.ts <= coalesce(join_cohort_next_ts, '2100-01-01')
where
cs.activity = 'session_started'
group by
1,2
)For the all the Aggregate relationships, the queries are identical to the above but the aggregate function changes from min() or max() to sum(), count() or avg()
I hope that was useful. For more SQL patterns follow me on Twitter @ergestx