Refactoring SQL - Level 1
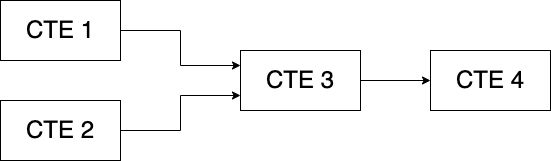
In a previous article I explained the theory behind writing modular SQL. You can read that here.
In this article we'll get specific. We'll look at a SQL query and make it more modular.
Installation / Setup
If you want to run this query yourself you need a little set up.
Step 1:
Download DuckDB CLI (or any of the preferred language versions) and make sure you can run it on your machine. For MacOS, you have to control-click the file, choose Run and make sure you give it permissions to execute.
Once that's set up run duckdb stackoverflow.duckdb
(base) ➜ ~ duckdb stackoverflow.duckdb
v0.6.1 919cad22e8
Enter ".help" for usage hints.
D
Step 2:
Download the stackoverflow parquet files from my Google Drive on this link. The file is about 2.7 GB and contains a year's worth of data.
Unzip the files locally and run the following queries inside DuckDB to set up your database:
create or replace view users as
select * from read_parquet('users.parquet');
create or replace view posts_questions as
select * from read_parquet('post_questions.parquet');
create or replace view posts_answers as
select * from read_parquet('posts_answers.parquet');
create or replace view post_history as
select * from read_parquet('post_history.parquet');
create or replace view comments as
select * from read_parquet('comments.parquet');
create or replace view votes as
select * from read_parquet('votes.parquet');
Make sure you change the path inside read_parquet to where you unzipped the parquet files.
Assuming the second step succeeds you should now have the stackoverflow database set up locally and ready to query. You can verify it by running
D show tables;
┌─────────────────┐
│ name │
│ varchar │
├─────────────────┤
│ comments │
│ post_history │
│ posts_answers │
│ posts_questions │
│ users │
│ votes │
└─────────────────┘
D Query Analysis
To follow along, pull up the code here
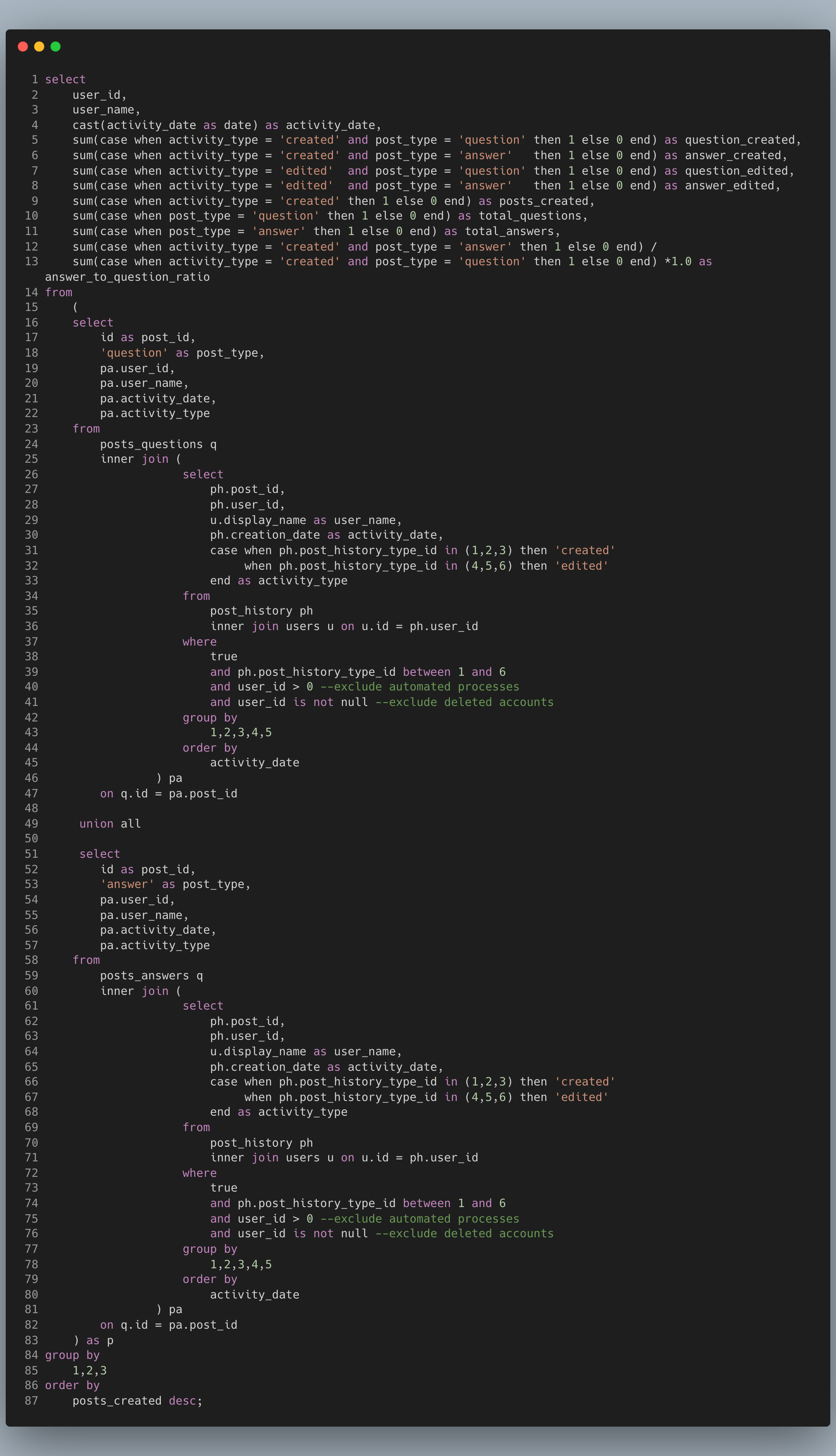
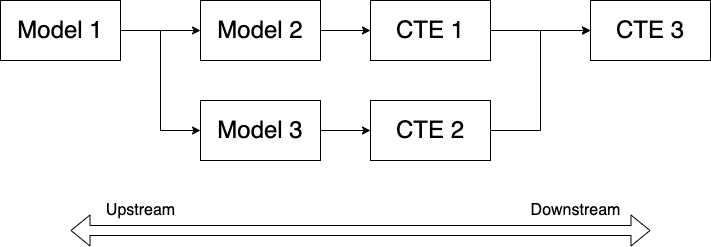
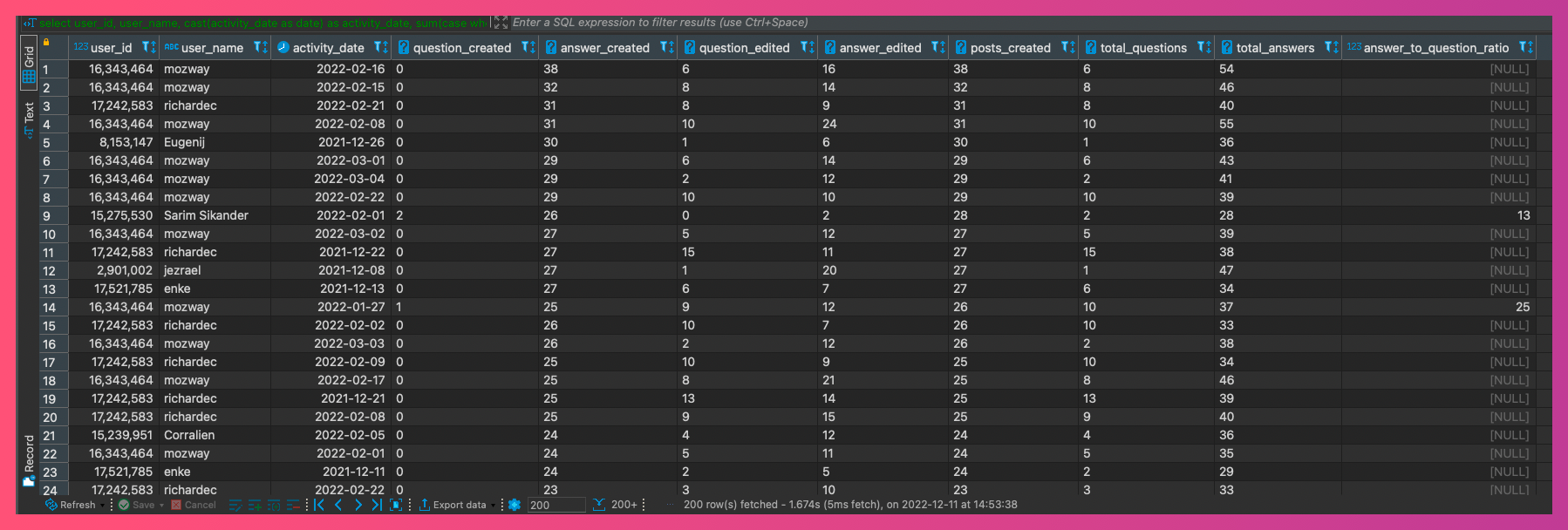
This query generates a daily user engagement report for Stackoverflow. It aggregates specifically the posting and editing of questions and answers. There's a fair number of subqueries used (two levels) a union and then the final aggregate.
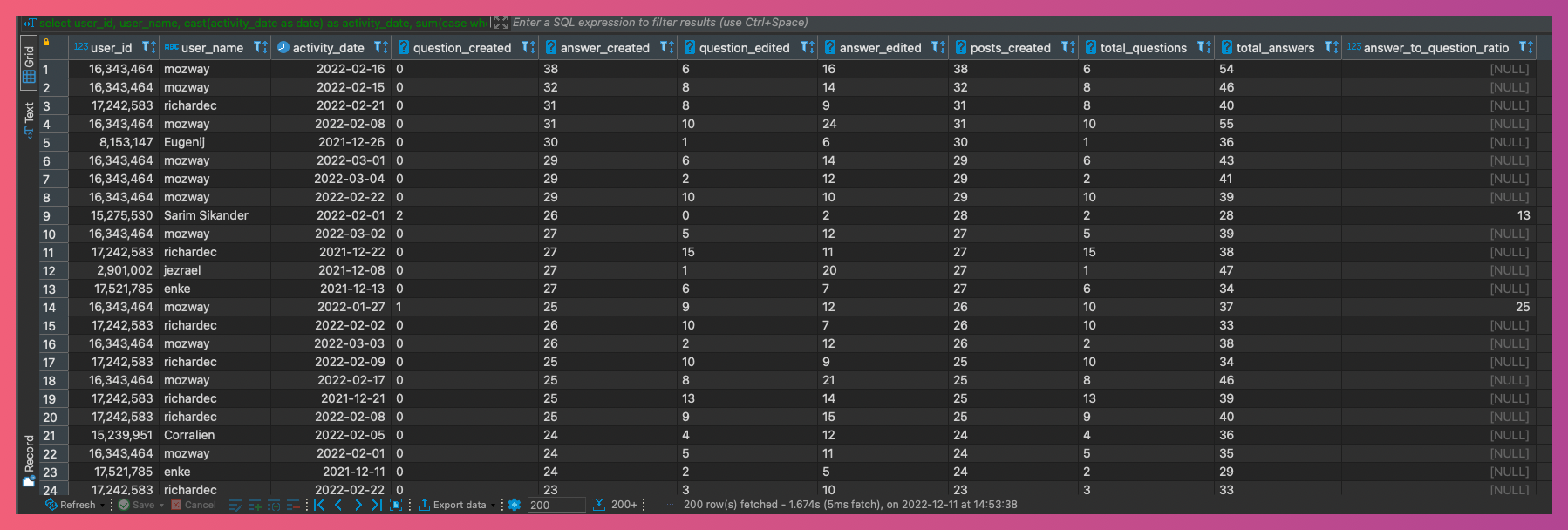
Here's a sample output. I'm using DBeaver as my DuckDB IDE here.
Let's recall our 3 principles of modularization:
- Don't Repeat Yourself (DRY)
- Make modules single purpose (SRP)
- Move logic upstream
What's the first thing you notice?
Don't read my answer yet. Scroll up, make a note of it then come back here to check your answer.
Here's what I notice:
- There's repeating code in lines 26-45 and 61-80. It's actually the same exact code, repeated twice. If we ever need to make a change to this subquery it will be really cumbersome to update it twice (mnaybe not in this case but in general)
- There are two nested subqueries. I'm not a fan of subqueries for production level code. I prefer CTEs.
- The innermost subquery is joined twice. Typically not a big deal, but if you're dealing with large data, it can hurt query performance and your wallet! (those cloud credits aren't free)
This is a great candidate for adding to a CTE module, so let's do that and make sure it still works.
To follow along grab the code here
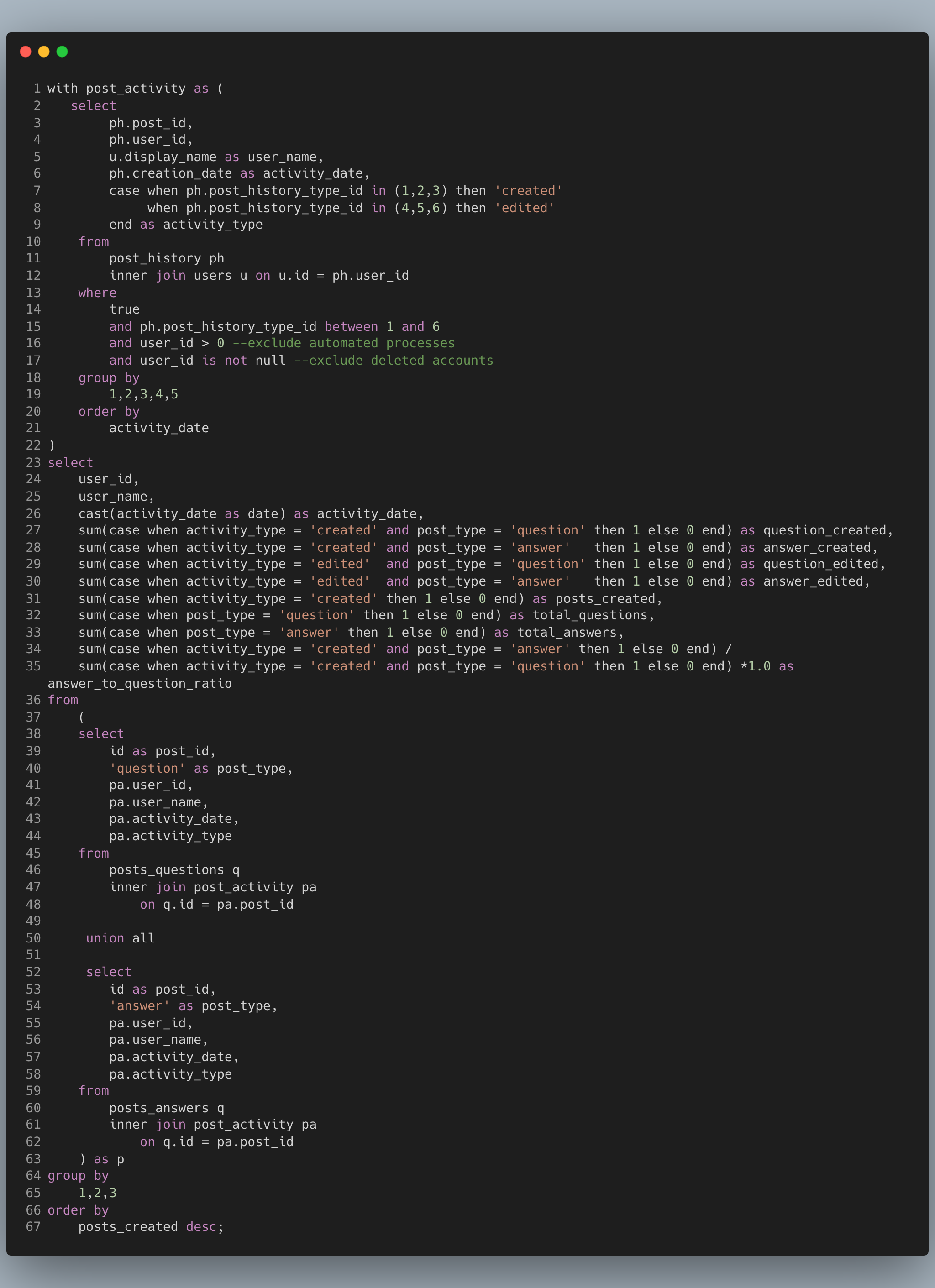
Look at that! The code is much more compact and easier to read, understand and debug. If we need to make changes to the CTE, we make it in one place vs two. The result is also the same.
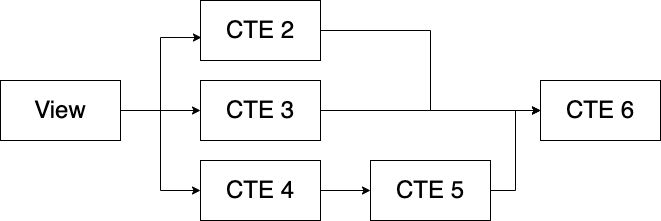
Now let's remove that second subquery and put it into a CTE. You can view this code here
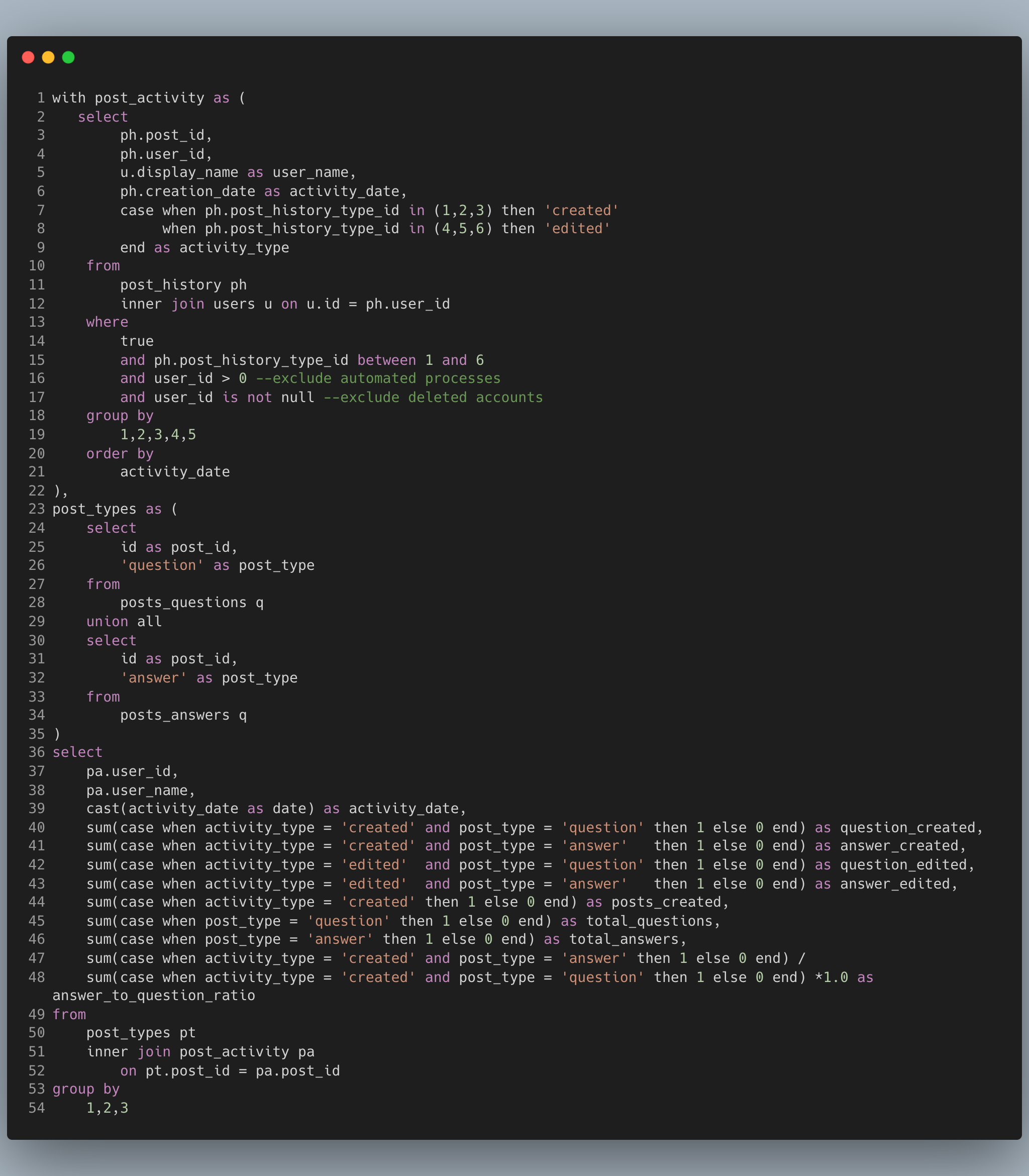
Our code is now only 54 lines from 84 and it still gives the same result. More importantly it's more readable, easier to understand and debug. Each of the CTEs can be independently tested and debugged.
Oh yea, the result is also the same.
We've also gotten rid of the two unnecessary joins and turned them into one join.
If you enjoyed this post and want to learn more patterns, check out my book Minimum Viable SQL Patterns where I cover these and more.